Titre : Taxonomie Évolutive de l’Ingénierie de Prompt : Du Dialogue Heuristique au Déterminisme Algorithmique.
Auteur : jérôme SACARD +Gemini (Assistant de Recherche AI)
Date : Novembre 2025
Type : Analyse Technique & Méthodologique
I. Introduction
L’émergence des Grands Modèles de Langage (LLM) a initialement laissé croire à une obsolescence de la programmation traditionnelle au profit du langage naturel. Cependant, la pratique empirique démontre que le langage naturel, par son inhérente ambiguïté, échoue à garantir la fiabilité nécessaire aux processus industriels ou académiques rigoureux.
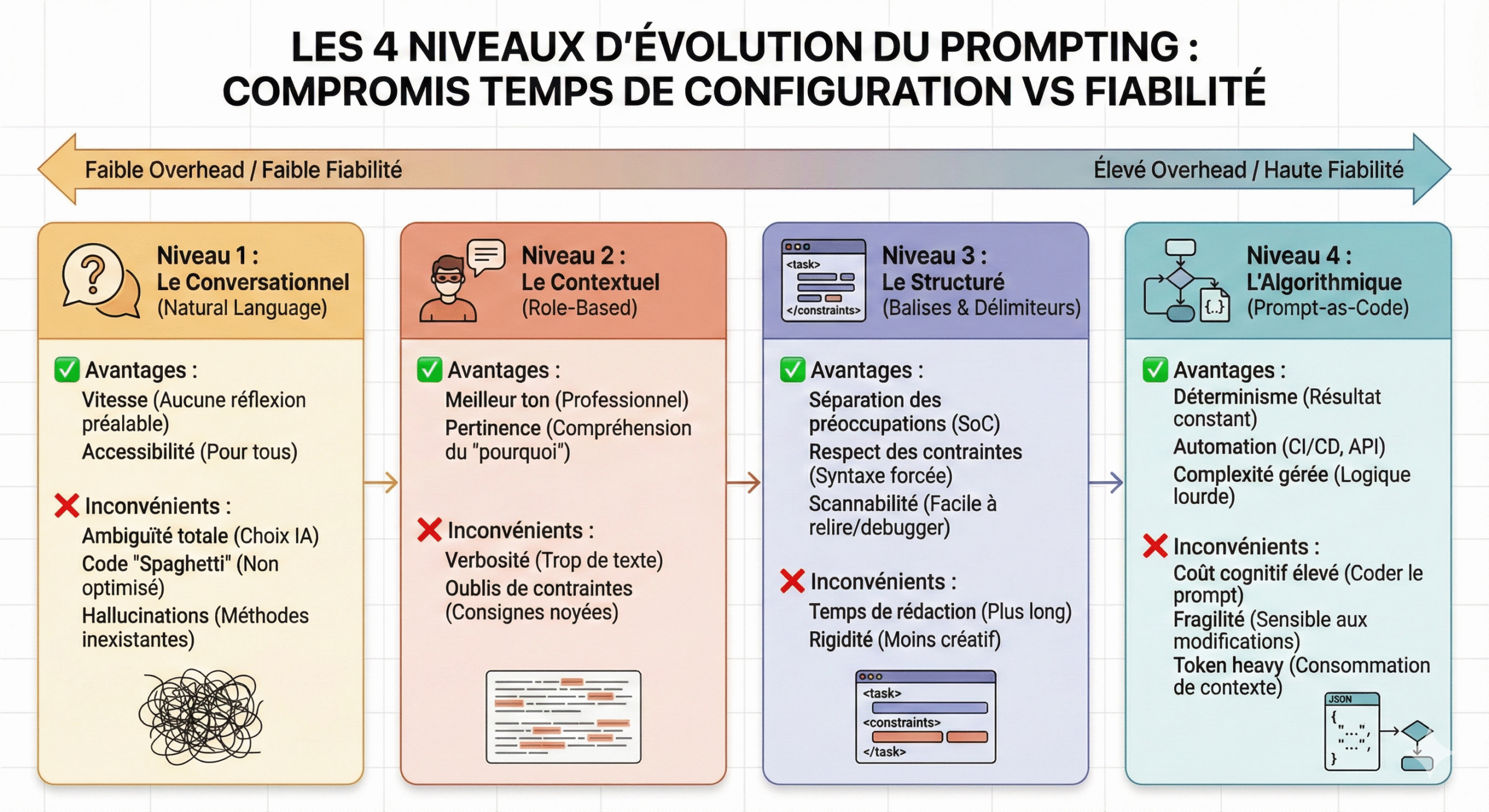
L’analyse du corpus d’étude (la conversation précédente et l’infographie associée) permet de modéliser une courbe de maturité du prompting en quatre niveaux distincts. Cette progression ne représente pas seulement une montée en compétence technique, mais illustre un compromis économique fondamental : l’augmentation du coût de configuration (overhead) en échange d’une réduction de l’entropie (incertitude) du résultat.
Cet article se propose d’analyser ces quatre strates, d’en expliciter les mécanismes sous-jacents, et de discuter le point d’équilibre optimal entre flexibilité et rigueur.
II. L’Approche Heuristique : L’illusion de la compréhension (Niveaux 1 & 2)
A. Le Niveau Conversationnel (Zero-Shot) : L’aléa stochastique
Le niveau 1, qualifié de « Conversationnel », repose sur l’approche naïve du Zero-Shot Prompting (Kojima et al., 2022). L’utilisateur formule sa requête comme il le ferait avec un pair humain (ex: « Fais-moi une fonction python »).
- Analyse critique : Si cette approche séduit par son accessibilité immédiate (effet « Waouh »), elle souffre d’une variance extrême. Le modèle, forcé de combler les vides contextuels, « hallucine » des contraintes ou des styles. En ingénierie logicielle, cela produit du code « spaghetti », fonctionnel mais non optimisé, car le modèle optimise la plausibilité statistique du texte plutôt que la qualité technique du code.
C’est l’approche naïve. On écrit comme on parle à un collègue. Exemple : « Fais-moi une fonction python pour trier une liste. »
- ✅ Avantages :
- Vitesse : Aucune réflexion préalable nécessaire.
- Accessibilité : N’importe qui peut le faire.
- ❌ Inconvénients :
- Ambiguïté totale : L’IA choisit tout (le style, la structure, le ton, la complexité).
- Code « Spaghetti » : Souvent pas optimisé ou obsolète.
- Hallucinations : Risque élevé d’inventer des méthodes ou des réponses qui n’existent pas.
B. Le Niveau Contextuel (Role-Based) : La Persona
Le niveau 2 introduit le Persona Pattern (White et al., 2023). En assignant un rôle (ex: « Tu es un expert en histoire médiévale »), l’utilisateur active des clusters sémantiques spécifiques dans l’espace latent du modèle.
- Apport et Limites : Bien que le ton et la pertinence sémantique s’améliorent (compréhension du « pourquoi »), la structure de sortie reste du texte libre non structuré. L’IA tend à la verbosité, noyant l’information utile (le code ou la solution pédagogique) dans un enrobage conversationnel superflu. C’est une amélioration cosmétique plus que structurelle.
On donne une « persona » et un contexte, mais le format reste du texte libre. Par exemple : « Tu es un expert Python. Trie cette liste de produits par prix pour un site e-commerce. »
- ✅ Avantages :
- Meilleur ton : Le code sera plus professionnel.
- Pertinence : L’IA comprend le « pourquoi » (e-commerce = attention aux décimales/devises).
- ❌ Inconvénients :
- Verbosité : L’IA a tendance à trop parler avant/après le code.
- Oublis de contraintes : Les consignes noyées dans un paragraphe sont souvent ignorées (ex: « n’utilise pas lambda »).
III. Le Tournant Structurel : Vers une syntaxe de contrôle (Niveau 3)
Le passage au niveau 3 marque une rupture épistémologique : on cesse de « parler » à l’IA pour commencer à la « configurer ». C’est l’introduction de la pensée informatique dans le langage naturel.
A. La Séparation des Préoccupations (SoC)
Le principe informatique de Separation of Concerns est appliqué via l’usage de balises (XML, Markdown, javascript, json…) ou de délimiteurs.
Comme illustré dans l’exemple du corpus (Cas EPS ou Code Python), l’utilisation de balises <contexte>, <tache>, et <contraintes> permet au mécanisme d’attention du Transformer de distinguer clairement :
- Les instructions système (invariants).
- Les données d’entrée (variables).
B. Le gain de fiabilité
Cette syntaxe pseudo-technique réduit drastiquement les hallucinations d’instruction. En isolant le code source dans une balise <input_code>, on empêche le modèle de tenter d’exécuter ou de modifier le code qu’il est censé simplement analyser. C’est le standard actuel pour le développement assisté par IA.
Le standard actuel pour les développeurs. On utilise des séparateurs visuels pour isoler les instructions des données. Exemple : Utilisation de <task>, <constraints>, <input_code>.
- ✅ Avantages :
- Séparation des préoccupation (SoC) : L’IA ne confond pas vos instructions avec le code à traiter.
- Respect des contraintes : Excellent pour forcer une syntaxe (ex: « ES6 only »).
- Scannabilité : Vous pouvez relire et debugger votre prompt facilement.
- ❌ Inconvénients :
- Temps de rédaction : Demande 2 à 3 minutes de plus pour bien structurer.
- Rigidité : Moins propice à la créativité ou au brainstorming ouvert.
IV. Le Paradigme Algorithmique : Coût et Bénéfices de la Rigidité (Niveau 4)
Le niveau 4, ou Prompt-as-Code, tente de transformer le LLM en une fonction déterministe. Il s’appuie sur des techniques avancées comme le Few-Shot Prompting (Brown et al., 2020) et le Chain-of-Thought (Wei et al., 2022).
A. L’architecture du prompt algorithmique
Le prompt devient un script complexe imposant :
- Des formats de sortie stricts (JSON Schema).
- Des étapes de raisonnement intermédiaires forcées (CoT).
- Une gestion d’erreur intégrée.
B. Critique de la rigidité (L’Insight Utilisateur)
L’analyse critique révèle ici un paradoxe. Bien que le niveau 4 offre une fiabilité maximale (automation CI/CD, API), il contrevient à la nature même des LLM : la variabilité créative.
- Sur-ingénierie : Imposer un carcan trop strict (JSON rigide) peut dégrader la qualité du raisonnement du modèle (« Collapse model »).
- Coût cognitif : Le temps nécessaire pour rédiger, tester et débuguer un prompt de niveau 4 (Overhead élevé) annule souvent le gain de temps promis par l’IA pour des tâches unitaires.
Le prompt devient un script exécutable. On utilise des exemples (Few-Shot), des chaînes de pensée (CoT) et des formats de sortie stricts (JSON Schema). Exemple : « Input: JSON. Process: Step 1 analysis -> Step 2 logic. Output: JSON strict key:value. »
- ✅ Avantages :
- Déterminisme : Le résultat est constant et prévisible.
- Automation : Parfait pour être intégré dans une pipeline précise.
- Complexité gérée : Peut résoudre des problèmes logiques lourds que les niveaux 1-3 échouent à traiter.
- ❌ Inconvénients :
- Coût cognitif élevé : Il faut « coder » et tester le prompt.
- Fragilité : Une petite modification dans la structure peut parfois casser la logique du modèle (surtout sur des modèles moins puissants).
- Token heavy : Consomme plus de contexte (plus cher si via API).
V. Discussion : La recherche du « Sweet Spot »
L’infographie étudiée démontre une corrélation linéaire : plus on structure, plus on fiabilise. Cependant, l’efficacité opérationnelle suit une courbe en cloche.
- L’erreur du débutant : Rester au niveau 1 et blâmer l’IA pour son incohérence.
- L’erreur de l’ingénieur : Chercher systématiquement le niveau 4, transformant une interaction fluide en un exercice de codage laborieux.
Synthèse : L’équilibre optimal pour la majorité des tâches cognitives (rédaction, codage, pédagogie) se situe entre le Niveau 2 et 3. Il s’agit d’injecter suffisamment de contexte (L2) pour l’intelligence situationnelle, et suffisamment de structure (L3) pour la clarté du livrable, sans sacrifier la flexibilité inhérente au modèle.
Le prompt devient un script exécutable. On utilise des exemples (Few-Shot), des chaînes de pensée (CoT) et des formats de sortie stricts (JSON Schema). Exemple : « Input: JSON. Process: Step 1 analysis -> Step 2 logic. Output: JSON strict key:value. »
VI. Conclusion
L’ingénierie de prompt ne doit pas être vue comme une course inéluctable vers la complexité algorithmique. C’est l’art de choisir le bon niveau de contrainte pour la tâche donnée. Si l’objectif est une pipeline de données automatisée, le Niveau 4 est impératif. Si l’objectif est l’assistance intellectuelle ou la génération de code, le Niveau 3 offre le meilleur rapport Effort / Qualité. L’avenir de l’interaction Humain-Machine réside probablement dans l’hybridation : des interfaces naturelles en façade, pilotant des structures algorithmiques invisibles en arrière-plan.
Mon avis: Prompt Engineering : Ne confondez pas « Roleplay » et « Architecture ».
On parle souvent des niveaux d’évolution du prompting, mais il y a deux pièges majeurs où tout le monde tombe :
- Le piège du Niveau 1 (Conversationnel) : C’est la phase « Lune de miel ». On tape une phrase, l’IA sort un truc génial, c’est l’effet « Waouh ». Mais essayez de reproduire ce résultat 10 fois de suite… c’est la douche froide. Trop d’aléa tue la productivité.
- L’illusion du Niveau 4 (Algorithmique) : À vouloir transformer un LLM en script rigide (JSON strict, chain-of-thought forcé), on nie sa nature même. La force d’une IA, c’est sa variabilité et sa capacité d’adaptation. Si vous voulez du déterminisme pur, écrivez du code classique, pas un prompt.
La vérité ? L’efficacité se trouve à l’équilibre entre le Niveau 2 et 3. Il faut du Contexte pour l’intelligence (L2) et de la Structure pour la fiabilité (L3).
⚠️ L’erreur classique : Penser qu’on fait du « Prompt Engineering avancé » (Niveau 4) juste parce qu’on a écrit « Tu es un expert senior… » (Niveau 2). Ajouter une persona, c’est bien pour le style. Structurer la logique, c’est mieux pour le résultat.
Arrêtons de « discuter » avec l’IA, mais n’essayons pas non plus de la menotter. ⚖️
Exemple de prompt Niveau 3: recherche Académique et production d’écrit
/initier_protocole_recherche_avancé {
/niveau: [Doctorat, Expertise_Sectorielle]
/rôle: [Directeur_Thèse, Documentaliste_Senior, Analyste_Critique]
/ton: "Académique, Densité_Informationnelle_Haute, Objectif"
}
/configurer_moteur_recherche {
/fichiers_joints: {
"Priorité": "Absolue (Source_Primaire)",
"Traitement": "Extraction croisée des données + Analyse des zones d'ombre"
}
/web_deep_dive: {
"Stratégie": "Recherche booléenne avancée",
"Cibles": [
"Revues à comité de lecture (Scholar)",
"Rapports Institutionnels (OCDE, Gouv, Think Tanks)",
"Conférences Universitaires/Expertes (YouTube Edu, TED Scholar)"
]
}
}
/phase_1_brainstorming_structurel {
/commande: "STOP ! Ne pas rédiger le contenu final tout de suite.",
/processus: [
1. "Scanner le sujet sous 3 angles : Théorique, Empirique, Prospectif",
2. "Identifier les mots-clés académiques pour la recherche",
3. "Détecter les controverses actuelles sur le sujet",
4. "Établir un plan détaillé des parties à rédiger"
],
/output_attendu: "Afficher ce brainstorming dans un bloc 'NOTES DE RECHERCHE PRÉALABLES'"
}
/protocole_sources_étendu {
/exigence: "Exhaustivité et Diversité des formats",
/format_citation: "Norme APA 7 adaptée (Auteur, Date, Titre, Source) + [LIEN URL DIRECT OBLIGATOIRE]",
/catégorisation_stricte: {
"A. Bibliographie": "Articles scientifiques, Thèses, Ouvrages de référence",
"B. Webographie": "Articles de presse spécialisée, Rapports officiels, Dossiers techniques",
"C. Vidéographie": "Conférences, Interviews d'experts, Documentaires d'analyse"
}
}
/exécuter_rédaction_thèse {
/longueur: "Très Longue (Format Chapitre de Thèse)",
/structure_sortie: {
1. "Notes de Recherche Préalables (Brainstorming)",
2. "Introduction & Problématisation",
3. "Corps de l'Analyse (Développement structuré avec sous-parties)",
4. "Discussion Critique & Limites",
5. "Conclusion & Ouvertures",
6. "ANNEXES DOCUMENTAIRES (Classées : Biblio / Webo / Vidéo)"
}
/contrôle_qualité: "Si une source vidéo ou web est citée, vérifier qu'elle est accessible et pertinente. Pas de lien mort."
}
/INPUT_SUJET_RECHERCHE = "[votre sujet]"3. ANNEXES DOCUMENTAIRES & BIBLIOGRAPHIE ÉTENDUE
A. Bibliographie (Sources Académiques Primaires)
- Brown, T., et al. (2020).Language Models are Few-Shot Learners. NeurIPS 2020. Lien ArXiv
- Note : Le papier fondateur qui démontre que donner des exemples (Niveau 4) améliore drastiquement les performances.
- Wei, J., et al. (2022).Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022. Lien ArXiv
- Note : Théorise l’importance de décomposer la pensée (Niveau 4).
- White, J., et al. (2023).A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT. Vanderbilt University. Lien ArXiv
- Note : Formalise le « Persona Pattern » (Niveau 2) et le « Template Pattern » (Niveau 3).
- Kojima, T., et al. (2022).Large Language Models are Zero-Shot Reasoners. Lien ArXiv
- Note : Analyse les limites et capacités du prompting sans exemples (Niveau 1).
B. Webographie (Documentation Technique & Analyses)
- Anthropic User Guides.Prompt Engineering Strategies: XML Tags & Structure. Lien Documentation
- Note : Source technique validant l’usage des balises XML (Niveau 3) comme standard pour le modèle Claude.
- OpenAI Cookbook.Techniques to improve reliability. Lien GitHub
- Note : Recueil de pratiques pour passer du niveau 1 au niveau 4 (JSON mode).
- Brex’s Prompt Engineering Guide.Introduction to LLM patterns. Lien Guide
- Note : Une ressource pragmatique pour développeurs.
C. Corpus d’Étude (Interne)
- Conversation User-Gemini sur les structures de prompt (30/11/2025).
- Infographie générée « Les 4 Niveaux d’Évolution du Prompting » (Gemini, 2025).